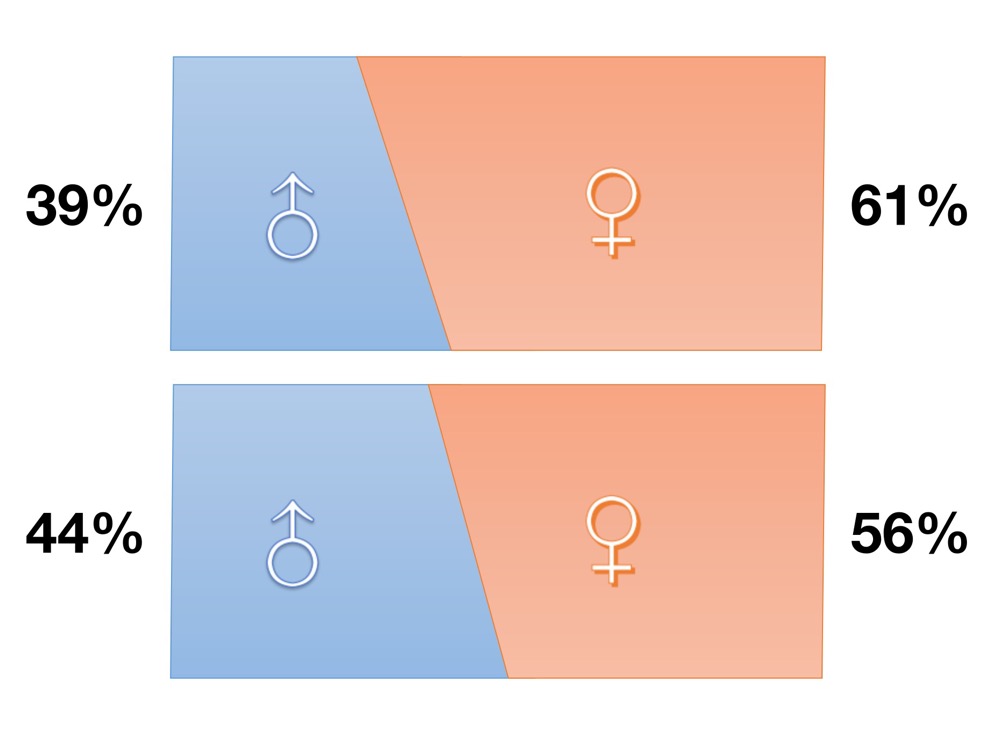
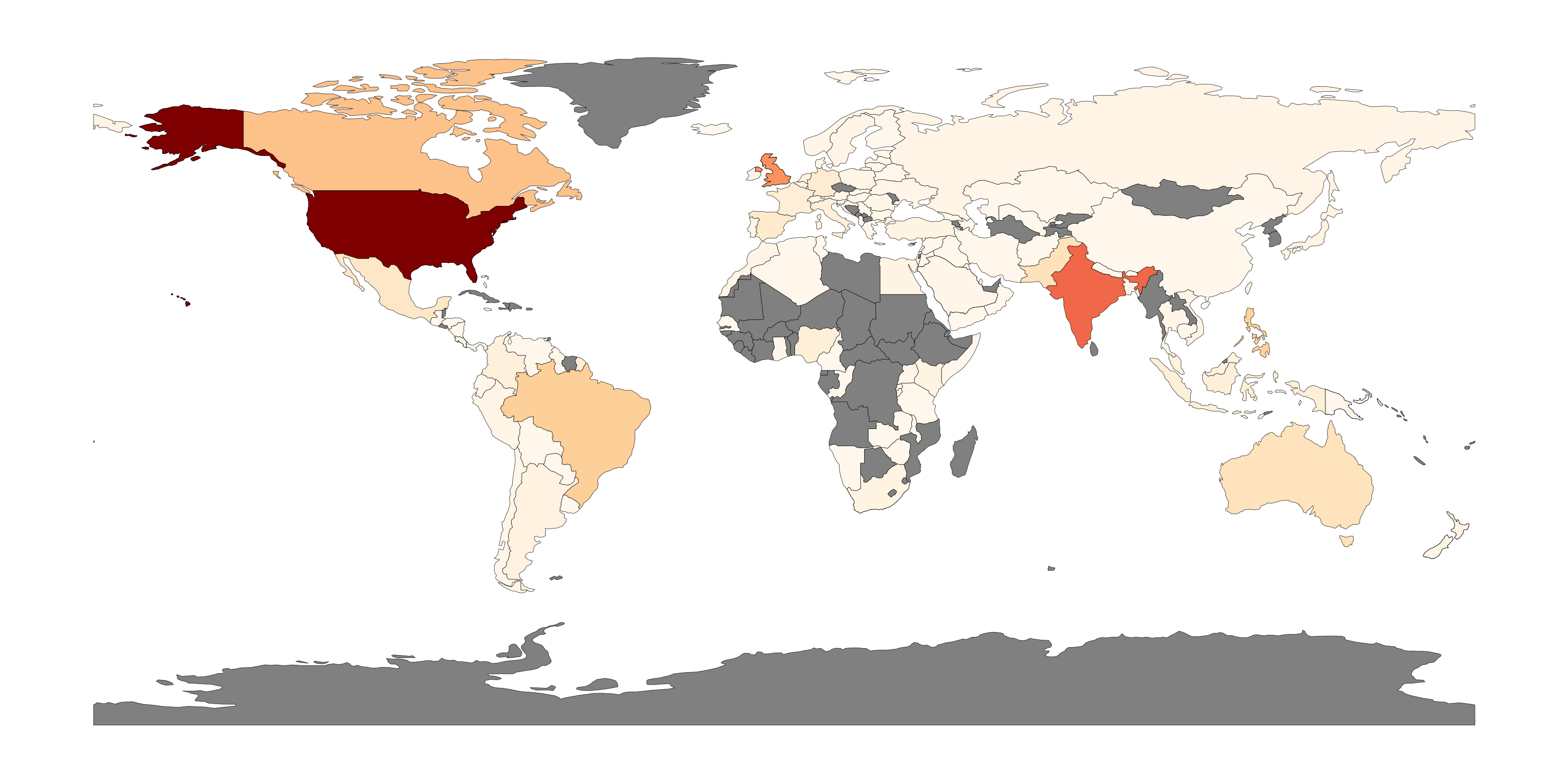
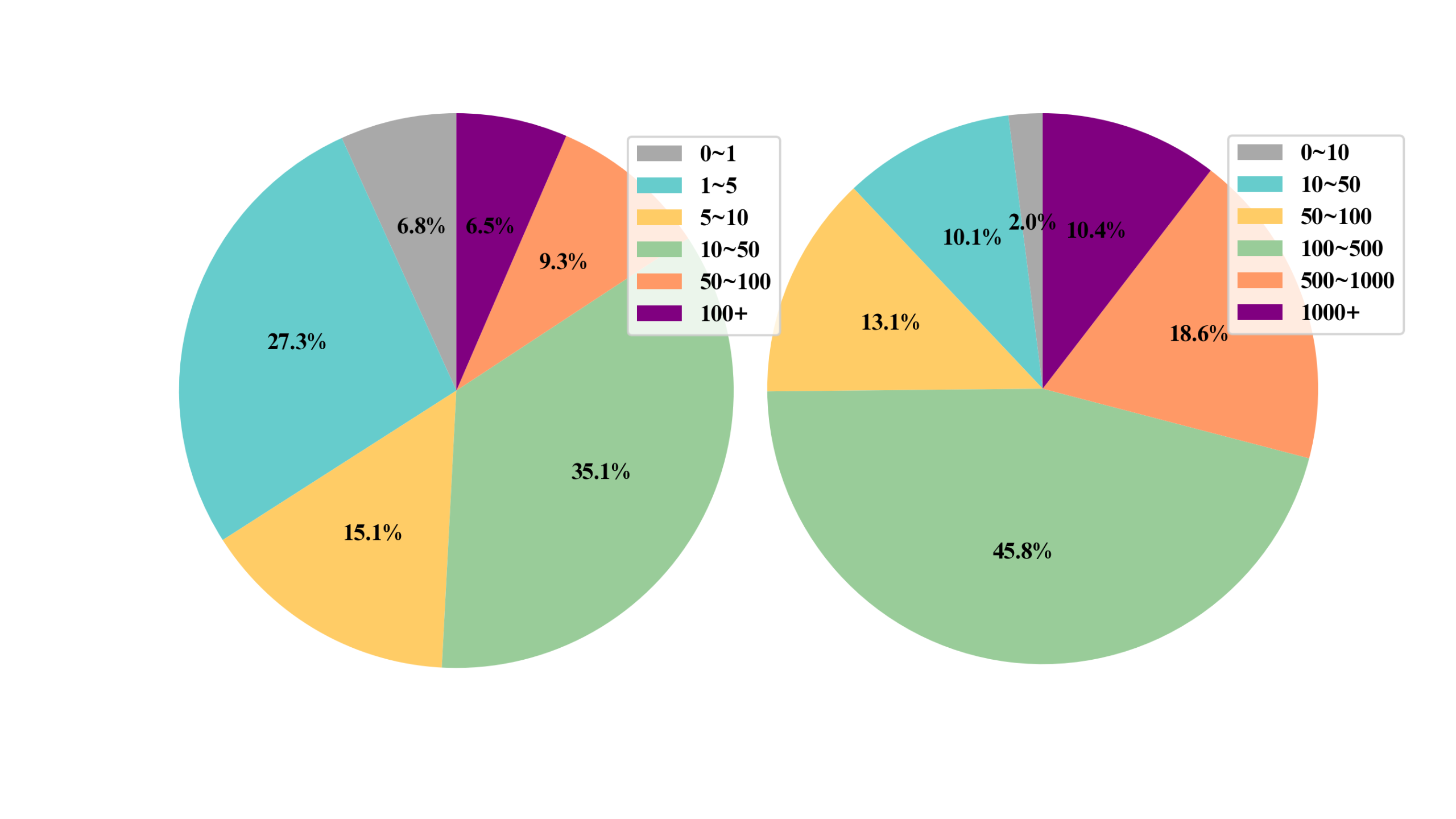
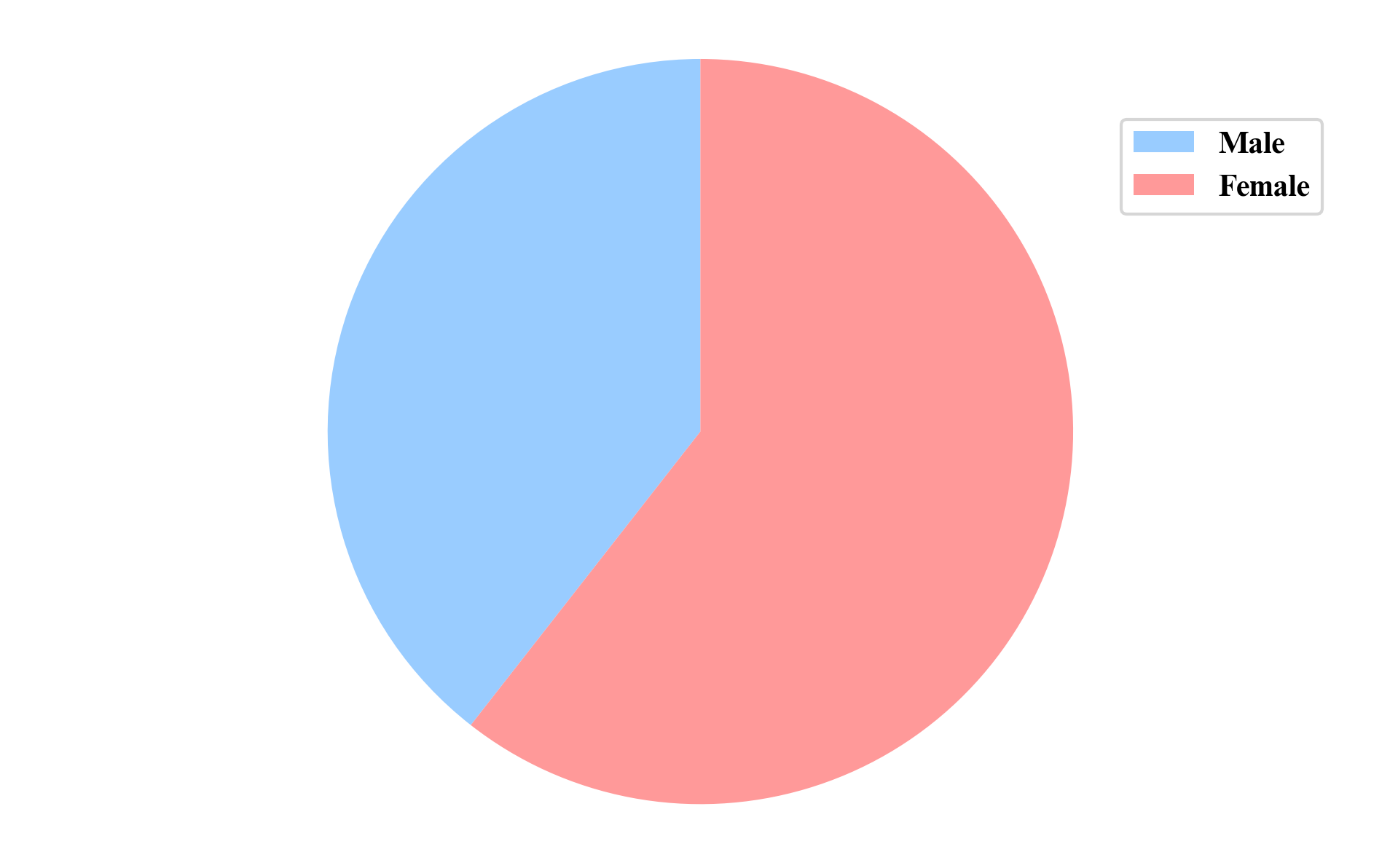
1.4M/1M+ Utterances
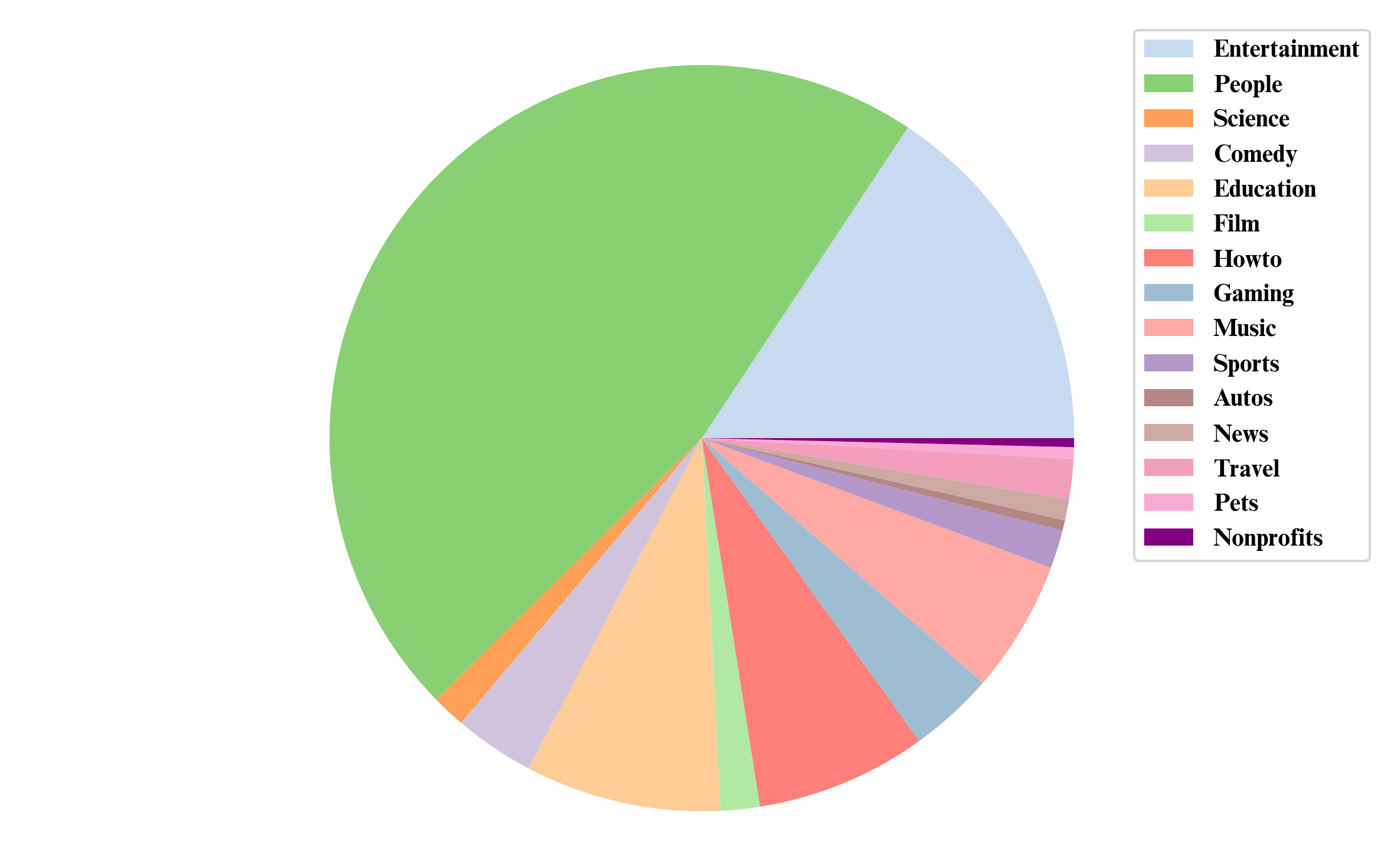
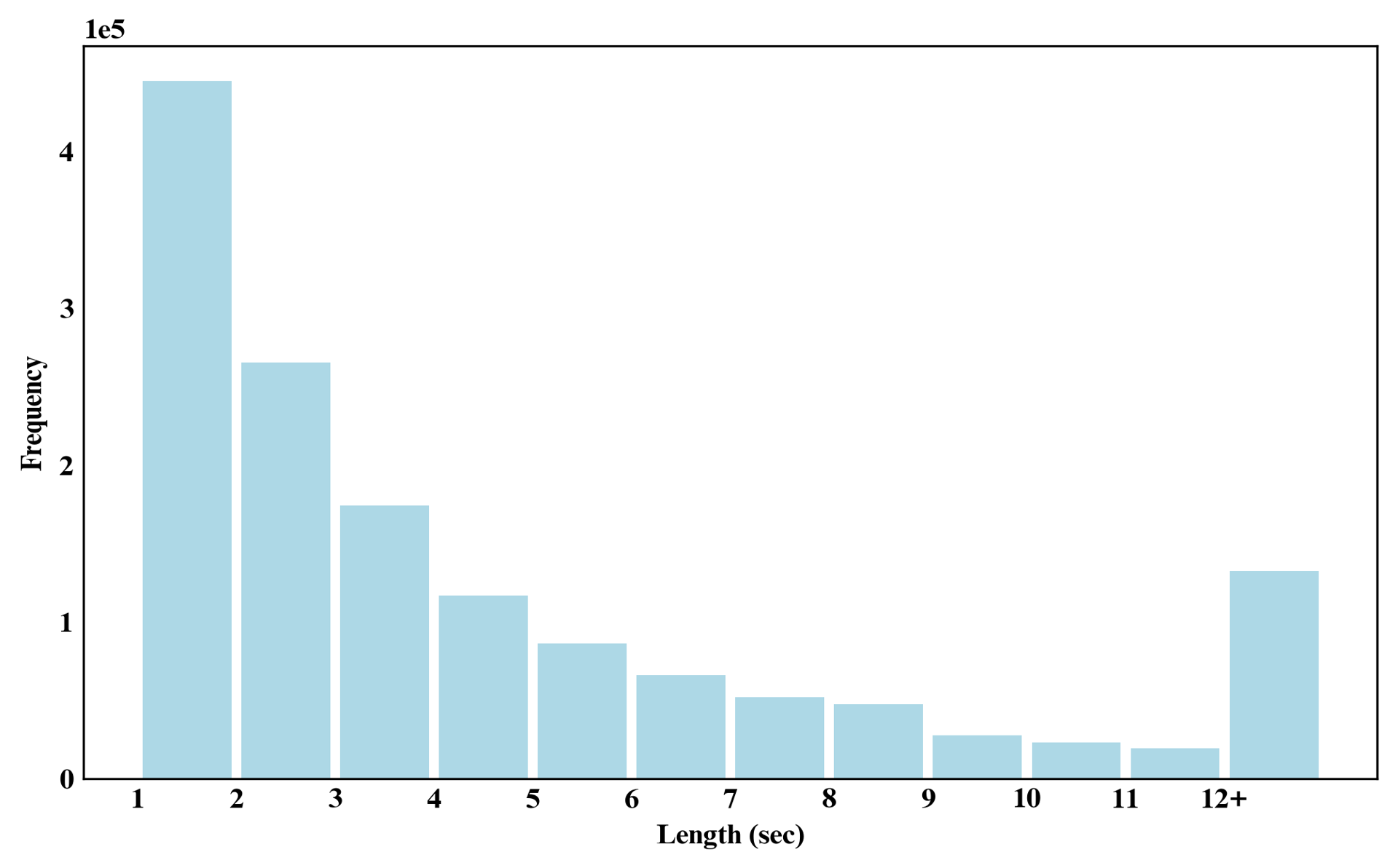
We annotate over 1.4M/1M audio/video segments from short videos on YouTube, encompassing various contexts including podcasts, lives, live streaming highlights, etc.
38K/18K+ Speakers
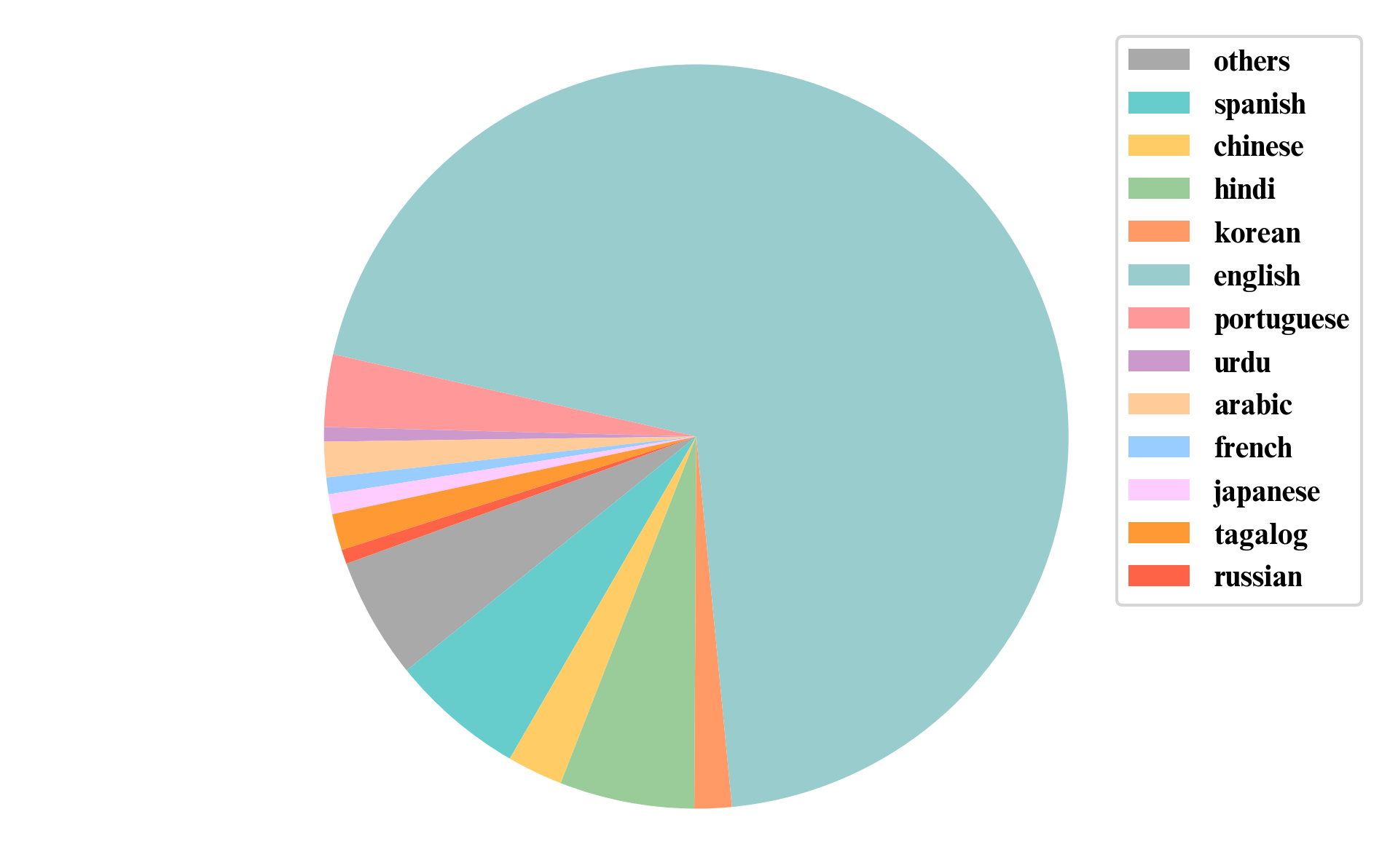
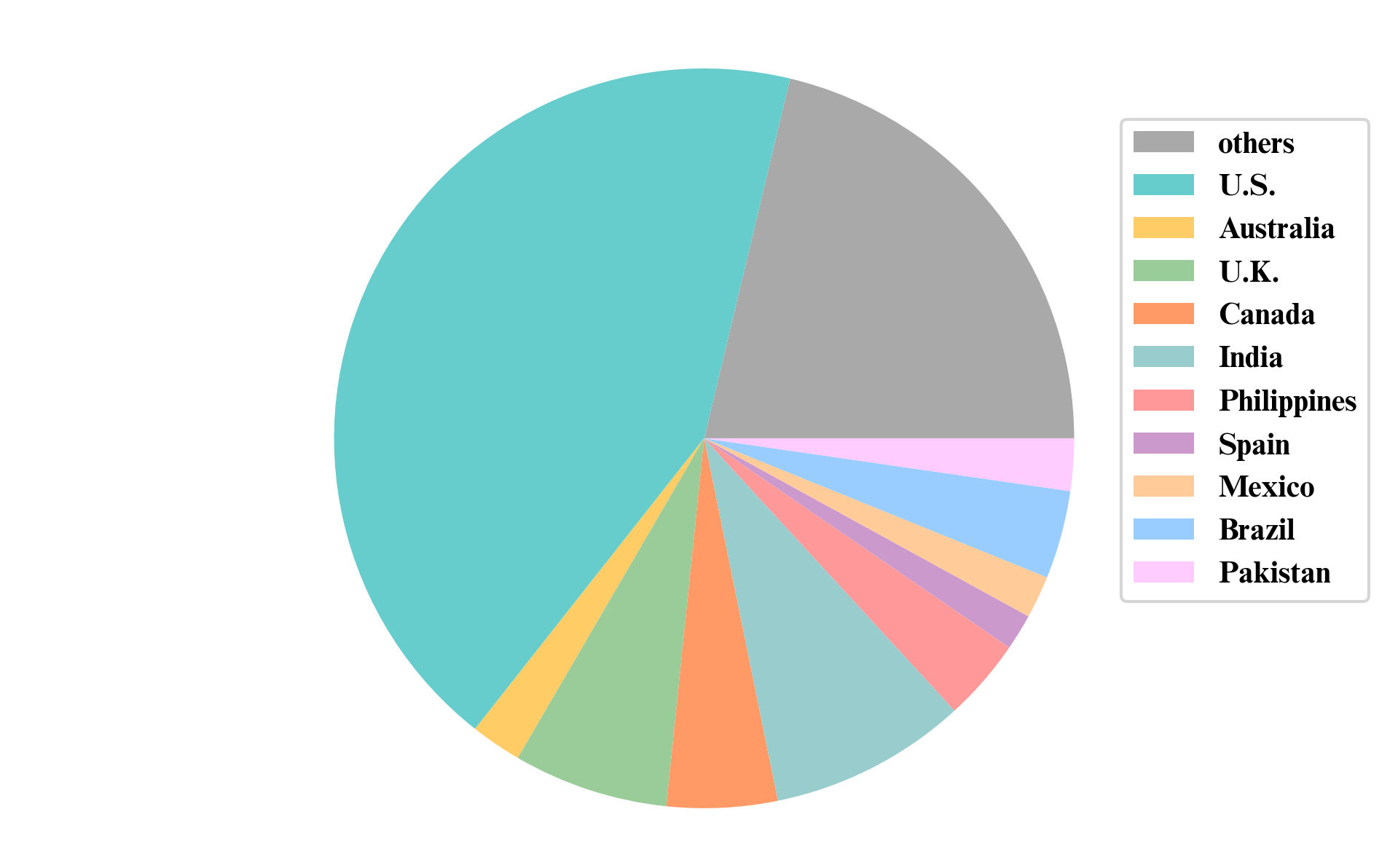
The speakers in our dataset come from 130+ countries, spanning multiple families of languages.
2100/1400+ Hours
The scenarios covered are more in line with real-life situations since we use short videos as the data source.
Features
Some new features about the VoxBlink and VoxBlink-clean!
Guidance
./video_tags folder.To get this, you need to decompress video_tags.tar.gz firstly. An example of these files can be referred in video_tag_example.
./timestamp folder. To get this, you need to decompress timestamp.tar.gz firstly. An example of timestamp file can be referred in timestamp_example.
./data. The utterances adhere to the following naming rules: speaker_id-video_id-utterance_id
./video_list. We provide three versions:
./meta.
./video_list and ./timestamp
Acknowledgement